
Podcast-DB: Feat Triform parallel actions

Find out **who’s talking about a company or person** in any Swedish podcast. Also just cool to have this kind of data and database.
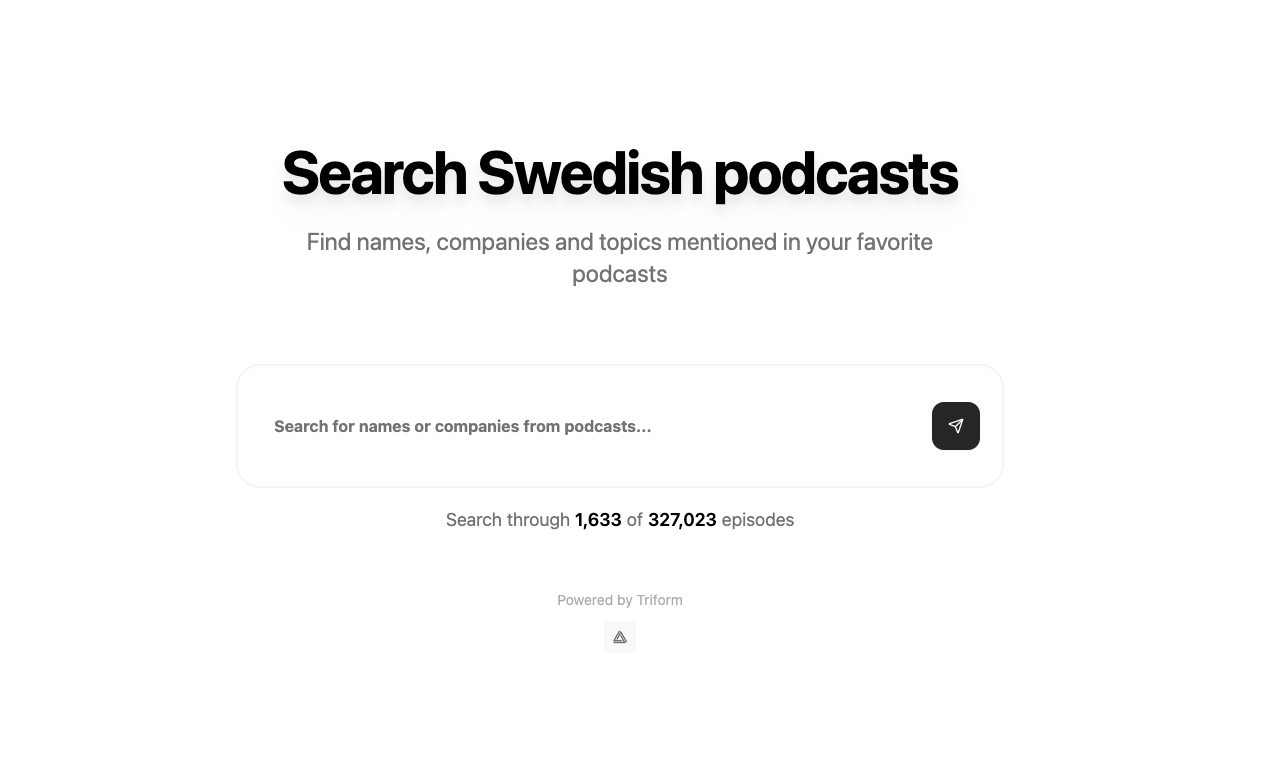
Last week, I decided to undertake a project to challenge myself: Find all Swedish podcasts, download them, and then transcribe them and build a search interface.
In this post, I go over the week journey end-to-end (mostly free time and over the weekend), starting from low infrastructure or any experience around building a podcast search engine. Some highlights:
- A cluster of 8 Hopper H200 GPUs transcribing over 300,000 podcasts
- At peak, 25 crawlers are downloading 250 podcasts in parallel (Downloading 9000 podcasts and hour).
- 12 TB of Audio data in our S3 bucket.
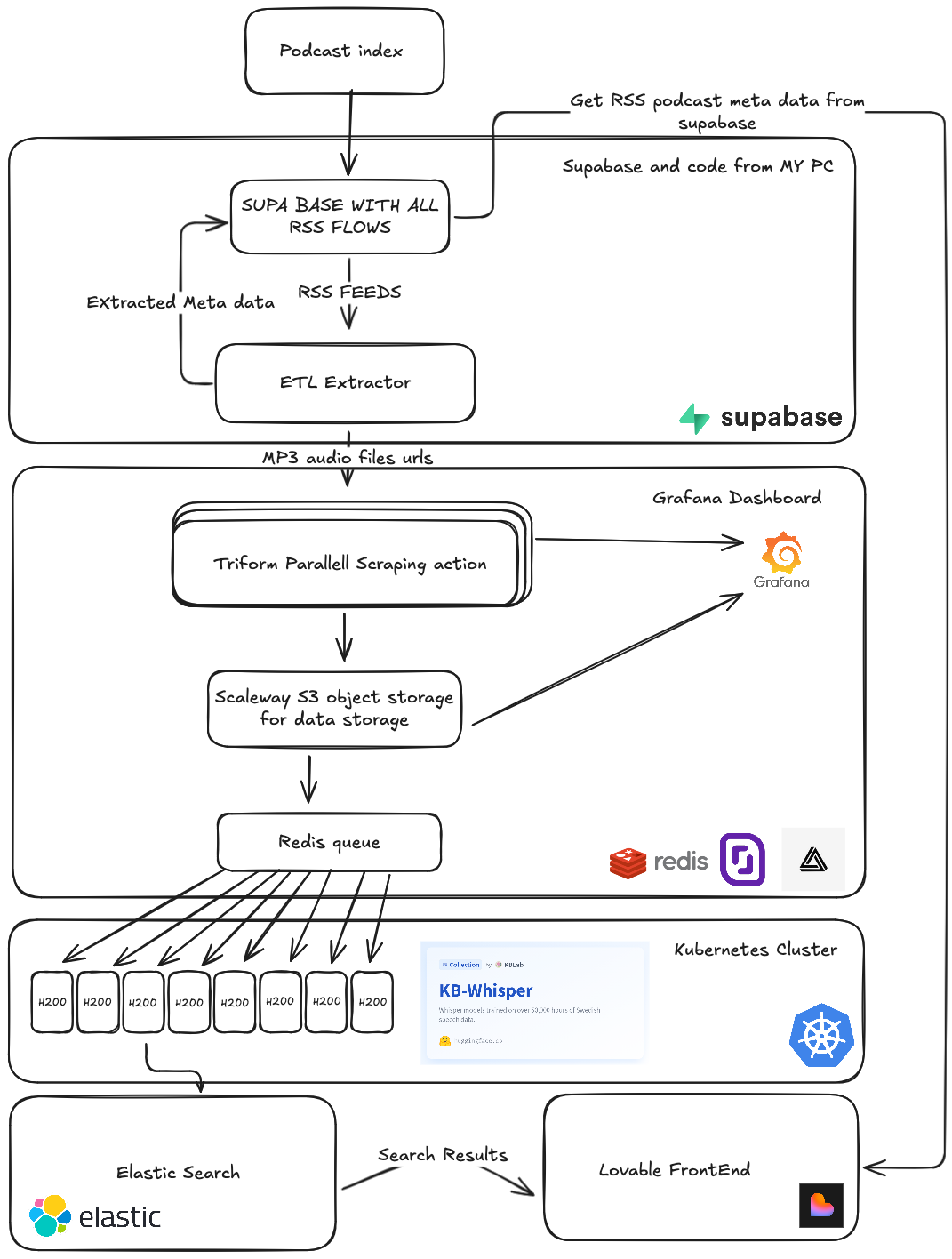
Here's a high-level architecture map of the system that will be covered in this post:
Proving ground
I started off by creating a minimal playground to experiment and explore if the idea was possible. I found a website that had done most of the work of collecting all the data called https://mediafacts.se/poddindex. By exploring their internal API calls, I found this endpoint:
https://api.mediafacts.se/api/podcast/v1/podcasts
From that call, we could get a dataset of 2400 podcasts with both name and an id.
{
"adb8141c-fb56-4092-6f88-08dbd636bc42": "#Fallet",
"e1e3a139-1b65-4a43-f843-08dbaa32d14e": "#FPLSVERIGE",
...
"866dcf58-058d-4468-b0da-08dd8c879318": "...och bilen går bra?",
}
With that ID, we can get full details:
curl --location 'https://api.mediafacts.se/api/podcast/v1/podcasts/details?id=857538db-0c16-4f7d-b053-08dc85405cb3'{
"rssFeedUrl": "https://rss.podplaystudio.com/1477.xml",
"podcastName": "Fallen jag aldrig glömmer",
"supplierName": "Podplay",
"networkName": "Bauer Media",
"genre": "Thriller/Crime"
}
Main target: rssFeedUrl Keep the rest (supplier, network, genre) for future analysis.
I’m using Supabase to store all data because I already have a Supabase subscription running. Now, from this mapping, I felt that the idea was possible; we just needed a lot of storage and computing to finish this project.
STATUS
Step 1 – Get podcast profiles Success rate: 99.04%
status_code Distribution:
================================================================================
200 2377 (99.04%)
404 19 ( 0.79%)
400 1 ( 0.04%)
410 1 ( 0.04%)
500 1 ( 0.04%)
503 1 ( 0.04%)
Total unique status_code: 6
Null/Missing status_code: 0
Conclusion: Minor data loss; we don't care to fix it now
RSS_request_status_code Distribution:
================================================================================
200 2315 (96.46%)
404 77 ( 3.21%)
400 2 ( 0.08%)
410 2 ( 0.08%)
500 2 ( 0.08%)
503 1 ( 0.04%)
0 1 ( 0.04%)
Total unique RSS_request_status_code: 7
Null/Missing RSS_request_status_code: 0
Conclusion: Here the data loss is a bit more significant but still enough.
RSS SOURCE DISTRIBUTION
Most feeds come from a few platforms:
Base URL Distribution:
================================================================================
https://feeds.acast.com 1136 (47.33%)
https://feed.pod.space 521 (21.71%)
https://api.sr.se 272 (11.33%)
https://rss.podplaystudio.com 150 ( 6.25%)
https://rss.acast.com 109 ( 4.54%)
https://podcast.stream.schibsted.media 94 ( 3.92%)
https://access.acast.com 70 ( 2.92%)
https://feed.khz.se 20 ( 0.83%)
https://cdn.radioplay.se 12 ( 0.50%)
http://www.ilikeradio.se 8 ( 0.33%)
https://www.ilikeradio.se 8 ( 0.33%)
Total unique base URLs: 11
Null/Missing RSS URLs: 0
Conclusion: This means that the structure is likely the same on all podcasts from each platform. Looking at the data, we can see that most of them follow the same structure with iTunes tags with the same names and titles and links, etc. That consistency makes the ETL pipeline easy to build and maintain.
RSS STRUCTURE
Most of them follow the same iTunes XML layout:
<item>
<title>705. Lex Birgitta Ed</title>
<pubDate>Thu, 23 Oct 2025 22:58:22 +0000</pubDate>
<guid isPermaLink="false">7258a43677f100f9d45ef43f19395a99</guid>
<link>https://pod.space/alexosigge/705-lex-birgitta-ed</link>
<itunes:image href="https://assets.pod.space/system/shows/images/397/fef/88-/large/Alex_och_Sigge.jpg"/>
<description><![CDATA[]]></description>
<enclosure url="https://media.pod.space/alexosigge/aos705.mp3" type="audio/mpeg"/>
<itunes:duration>00:59:21</itunes:duration>
</item>